This article covers how SEGGER vastly improved its documentation process by taking control of the tools we use and, in the process, removed reliance on FrameMaker.
On documentation…and why FrameMaker is a poor choice
Many of SEGGER’s manuals were written with FrameMaker, a well-respected technical authoring package widely used throughout the software industry. Unfortunately, maintaining documentation in FrameMaker is a royal pain.
FrameMaker itself is prone to crashing, uses a binary document format that is not human-readable, and comes with a steep learning curve when using it for the first time.
It gets worse when you start to use it for big projects: Documents become long and unwieldy, they are hard to move through, customizing them for different variants of a product using variables is complex and highly prone to error. Adding the document to source control, as it is binary, means each commit is another megabyte binary blob rather than a small delta.
Something as simple as finding the difference between two documents means using FrameMaker to do the comparison, which is almost impossible. And technical authors hate it because its legacy Unix user interface grafted onto Windows makes it feel awkward, unusual, and stuck in a timewarp.
But the biggest failing of FrameMaker is that its efficient storage format, binary, means that it is not able to be part of a workflow where documentation automation allows customization of the final output by simple text processing tools. (Yes, I know about MIF and SGML, been there, done that, I have the scars to prove it, it’s the software equivalent of a slow-motion car crash.)
Introducing emDoc
Realizing the obvious sinkhole of engineering time that FrameMaker opens for unsuspecting customers, I set out to develop a solution that worked for me. This solution is now at work every day in SEGGER, and it’s called emDoc.
emDoc uses a plain-text markup language, not so dissimilar from TeX, and is tailored to SEGGER’s documentation requirements. The benefits of using plain old text are many, here are a few:
- Its easy to edit text, efficiently, using your favorite text editor with keystrokes and a menu structure you use every day as a developer.
- Checking in a new revision of a manual is just a small delta.
- To compare two versions of a manual, use a regular or enhanced “diff” tool that you use for comparing regular source code.
With a plain text format you simply employ the tools you use for coding every day, no applications with special formats and menu layouts designed for maximum irritation, no misery of using FrameMaker or Word.
Letting go of the WYSIWYG immediacy, the efficiencies of using a plain text format and razor-sharp tools go so much further
Because a manual can be constructed from pieces, pulling together standard macros, front matter, and boilerplate for new manual builds is easy. But this just scratches the surface of what our multi-capable tool, emDoc, can do to ensure software and documentation quality.
And because SEGGER control the tools necessary in this workflow, we are not reliant on patch releases, stuck-in-the-80s software, or the continual payment of maintenance for no appreciable increase in productivity or functionality. There is no doubt that being tool-smith in total control of your workflow is essential and isolates you from software disruptions when your supplier drops the ball. Or the product.
Scaling documentation with software
Let’s take emCrypt and its manual as an example. This manual runs to just over 2,600 pages covering how the software is delivered, how you use it, has many example code listings, and includes a complete API reference and index. The emCrypt core software is 5MB of code and the validation suite is 115 MB of code. It’s a big product. Keeping manual and software synchronized is a key task that is laborious and highly prone to error. emDoc makes this task a breeze!
SEGGER’s coding standard specifies how a function header looks, and it’s quite clean, for instance:
/********************************************************************* * * CRYPTO_HASH_SHA256_Final() * * Function description * Finalize digest calculation. * * Parameters * pContext - Pointer to hash context. * pDigest - Pointer to object that receives the message digest. * DigestLen - Octet length of the digest. * * Additional information * After calling this function, the context is destroyed * and must be reinitialized to be used again. The entire hash * context is set to zero to ensure no cryptographic material * remains in memory. */
When editing or debugging source code, you have some help from the header. But as this header is in a standard format, mandated by the SEGGER coding standard, it is amenable to extraction by a tool. In fact, the headers were not designed to be extracted by machine, but because every piece of SEGGER source conforms to these rules, extraction by machine is made possible with appropriate tooling.
That’s what emDoc does: it extracts all the header material so that it can be placed into the manual. This means that the documentation is edited in one place, in the code, and the manual follows along for the ride. Because you don’t need to fire up FrameMaker to write documentation, there’s a much higher chance that the documentation is correct, and you are 100% sure that the documentation in the manual mirrors what’s in the source code! And it’s not seen as a chore, it’s just efficient, so adding the documentation as you go becomes a natural, flowing part of the software development process and can almost be pleasurable!
Other documentation tools do similar, such as Doxygen, but you tend to write the whole of the manual in your source code and your source code is a casualty as it becomes littered with “backslash markup.”
SEGGER’s solution is clean, tidy, beautiful, and…entirely efficient.
Marking up
Inserting function, structure, or other source-resident documentation into the manual is no more than deciding which level to use for the heading:
\R4 CRYPTO_IO_EC_PEM_RdPublicKey \xall
The “xall” is a macro that copies the standard SEGGER sections into the manual in a prescribed order, along with the function prototype, structure definition, or enumeration. emDoc even deals with the common idiom of a set of preprocessor symbols that describe a bitmask or something that should be considered the equivalent of an enumeration. Yes, it’s that good.
Here is the emDoc source that documents the generic SHA-256 interface offered by emCrypt:
\H3 Generic API
The following table lists the SHA-256 functions that conform to the
generic hash API.
\table{50%,50%}
|| Function | Description
\summary{CRYPTO_HASH_SHA256_Init}
\summary{CRYPTO_HASH_SHA256_Add}
\summary{CRYPTO_HASH_SHA256_Get}
\summary{CRYPTO_HASH_SHA256_Final}
\summary{CRYPTO_HASH_SHA256_Kill}
\endtable
\R4 CRYPTO_HASH_SHA256_Add \xall
\R4 CRYPTO_HASH_SHA256_Final \xall
\R4 CRYPTO_HASH_SHA256_Get \xall
\R4 CRYPTO_HASH_SHA256_Init \xall
\R4 CRYPTO_HASH_SHA256_Kill \xall
This is what the above summary table looks like when formatted:

Of course this capability is extensible, enabling you to add more sections on a per-product basis (for instance the Bluetooth stack has sections that reference definitive Bluetooth specification paragraphs, and transcribing those is easy.) You just add any additional documentation you need as required as emDoc is totally flexible in the way that you arrange documentation. And it’s programmable.
This shows the function section formatted by emDoc with all the documentation extracted, parameters organized, and so on:
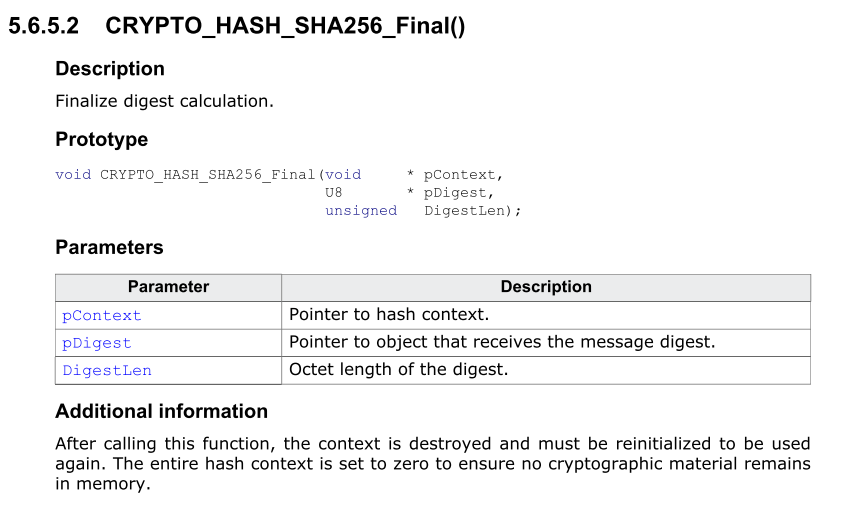
Autoformat…because we can
emDoc also formats the function prototype according to SEGGER rules, lining everything up appropriately. It also does things you wouldn’t expect, such as ensuring that if a formatted parameter would wrap a line, all parameters are moved below the function name and aligned right as a block, maintaining perfect formatting. With this single capability, no engineer needs to even consider that their function prototypes will look awful and wrap badly and need manual adjustment to the format. This is the embodiment of the SEGGER mantra: It Simply Works!
And, of course, emDoc can do syntax highlighting as it parses the function prototype and knows it’s written in C. So the printed manual gets perfectly-formatted, perfectly syntax-highlighted prototypes without any human intervention. This is what a tool should do. Again, it should simply work.
One of the great capabilities of emDoc is that it can pull in source code, format, and syntax highlight it for the manual. That means that the examples that ship in a distribution match exactly the examples that are in the manual, in all their syntax-highlighted beauty. Of course, emDoc knows how to syntax-highlight a wide range of languages, including scripting languages. These simple things make the documentation task so much easier and 100% accurate: no more forgotten transcriptions of source code into documentation!
Autolinking and autoindexing…because we can
As emDoc can reason about the inputs given to it (the manual source and the source code of the product) it is able to automatically link items to sections in the manual. If a code listing has a documented identifier in it, or just appears in regular body text, emDoc automatically links that identifier to its API reference section; in FrameMaker, this must be done manually. And emDoc will automatically format that identifier in monospace without the engineer needing to place any markup around it. And it automatically adds an entry into the index under the function name.
emDoc can create any “automatic” index for you, such as an index of functions, or of types. Just ask it. And it supports regular subject indexes. Engineers don’t need to think about linking and formatting because emDoc takes care of it, and does it automatically, correctly, each and every time.
emDoc knows about each function synopsis from the source code and can automatically pull that synopsis into a “summary table” which brings together the documented functions in a particular section (that’s the table in the example above). It’s all about making the machine do the work and relieving the engineer from the rote-boredom of doing it himself.
emDoc…the “lint” for documentation
It doesn’t stop there. emDoc parses the whole of a file, understands C code, and looks into comments to build a detailed view of the source structure.
emDoc can enforce SEGGER’s coding standards by ensuring that every function has a corresponding header, that every function header documents each parameter–in the correct order–along with any return value
And it can enforce major section ordering. And it knows about standard headers and can diagnose spelling mistakes (as English is not the native language of SEGGER’s engineers.) So emDoc is really useful as an external tool plugin for Embedded Studio or Visual Studio. I use it in both places and assign the key combination Alt+K to it. And because emDoc issues errors in a format both IDEs understand, it’s a breeze to move through your source code correcting any errors picked up by emDoc.
And I can go on. For instance, when you supply the source code of a product to emDoc, along with the header file that exposes this to the user, emDoc can reason about the contents of the package as a whole. It will tell you about anything that appears in the header file that does not appear in the manual, for instance, enabling you to quickly identify things you didn’t get around to adding to the documentation. How cool is that? Quality matters.
How efficient is emDoc?
Well, I’m not talking about how fast emDoc works, though it is blazingly fast. No, the efficiency here comes from the reduced time to make precise documentation, time that is better put into engineering, and the assistance emDoc provides when checking your documentation headers. And developer well-being is assured from not dreading the chore of documentation at the tail end of a project.
emDoc increases both developer productivity and product quality at the same time, something of a rarity.
Remember the numbers I mentioned earlier? 5 MB of code, 2,600 pages of documentation? The efficiency of emDoc can be measured by the fact that the emCrypt manual sources in emDoc format are about 500 KB as all the API documentation is held in clean, uncluttered, no-backslash-in-sight source code and is extracted automatically. The PDF manual is about 8MB, and that is with PDF’s built-in compression. So I think I’ve demonstrated that using emDoc provides efficiencies that a FrameMaker-based workflow is incapable of, and goes well beyond what you could ever achieve manually.
emDoc is a key tool in ensuring software and documentation quality in SEGGER. Period.
Wrapping up
Hopefully this post, although a bit long and rambling, reveals a little about the development process in SEGGER and the internal tools that we use to deliver quality products. It’s not about getting a MISRA stamp of approval. We actually found MISRA in a number of places to be counterproductive, forcing us to convert perfect code into something full of casts, hard to read, much longer and therefore also errorprone. Quality products require pride and craftmanship, and the same is true for software products.
Remember, a high degree of automation in the production of cars and machinery improves the quality of the end product, and tools such as emDoc eliminate avoidable human errors and improve the quality of our software products. It really is that simple.